Searching and filtering in Inuko apps
To quote captain obvious, we humans spend a lot of time searching. For socks, keys and phones all the way into the digital world. So much in fact, that one of the most valuable companies is the search engine. Now if that is so obvious, why do most apps provide such a broken search experience?
Why searching and filtering is hard
Short answer is: it is hard to build and hard to secure.
Read on for the long answer.
Pre-defined search options
One of the top security issues is sql injection, thus the recommendation is to use only prepared parametrized queries. Translated, that means programmers prepare a search query and you the user can only provide the parameters.
For example you can search for clients by name or address. But not both. And only by prefix, not suffix. If you need more, the app will have to be modified. Not flexible at all.
Now if the app is custom made for a single customer, and the customer is wiling to pay for changes, this might work. As more and more queries and parameters are introduces, the code will get harder to maintain. Still for a well defined narrow use-case this is a reasonable approach.
Dynamic search
For multi-tenant apps, adding queries on demand will not work. Thus we need dynamic search queries, defined by the end user. The user can choose the fields, operators, values and even combinations of them. That almost always translates to dynamic (on the fly) sql generation, which is a big no-no in security.
Exposing raw SQL to the user is a complete non-started. Thus over the years vendors introduces multiple query languages. From standards like OData and GraphQL to proprietary ones like Salesforce’s SOQL and Microsoft’s FefchXML.
Getting it right is quite the challenge.
Security
The query has to be handled with utmost care, assuming the worst. Here even the choice of format eg custom vs xml vs json matters. Xml has many weird corner cases and features that are long forgotten, but can be exploited.
Thus we believe JSON as the outer format makes a lot of sense. It is primitive enough and widely deployed that exploits are unlikely.
Still the actual content of the query has to be checked in an extremely paranoid way. That means if the user can choose a field and value, we have to ensure the field name is a text value, is not too long, doesn’t contain special characters, or keywords and actually exists in the schema. The value has to be treated in a similar fashion. This is hard to get right and easy to miss something. Because of that, we intentionally limit field names to 100 chars of a-z 0-9 and _.
Resource limits
Next problem has to do with how many fields can the user add to the query. Or there might be a constraint that at least one parameter is always present. Of course a limit on the number of results must be also considered. In general a technically valid query can consume too many server resources. Multiple such queries can lead to an unresponsive or crashed server, what's called DOS (denial of service).
For example if a condition is on a field that lacks an sql index and the table is large. Or the query contains an ‘order results by’ request which again is not covered in an index. A large number of results will consume a lot of memory (and/or sql tempdb space). The problem is made worse by the fact that it can be caused by a user who did not intend to do harm.
The only solution here is to add limits. On the query options, but also on the number of queries a single user can issue at once, and the maximum duration (and possibly memory size) of a single query.
At the end of the day, with a sufficiently large database, (non trivial) queries that are not optimised by indexes, will be slow. Too many slow queries will exhaust server resources, causing delays for all users. Of course with proper monitoring indexes can be added where needed. However this will not help against a determined attacker, especially if anonymous access is allowed and thus we cannot use per user resource limits.
User experience
It is one (complicated) thing for our app to provide programmer access to dynamic queries. How to make it available to end users is quite another. We are looking at three levels of “query” languages.
- At the bottom we usually have SQL.
- In the middle is the app’s dynamic query language.
- Finally there is a visual GUI “language” that the end user will work with.
Moving between level requires efficient translation.
If a 2 level language doesn’t map well onto sql, it will need to first read a lot data into memory, the do the search and then discard the rest. Which is obviously very inefficient.
The search UX (level 3) should supports most level 2 features, or otherwise the level 2 complexity is hard to justify. It will also complicate the app design, where some queries can be build visually and some not - requiring a separate edit mode.
Inuko approach
Our approach to search is to provide multiple tools so that the users can choose the right tool for the job at hand.
First of all our level 2 query language is JsonFetch. It maps well onto sql. It is primitive enough to be validated efficiently. It is also composable and hierarchical, which means combining queries is easy. Also that makes it rather straightforward to build visually.
The tools built on top of the query language. App designer can
- Define object list pages, each with its own query. Fe: My clients, All clients, etc.
- Add user selectable field filters to a list page. For example client status filter or start-date filter. Each filter can be individually secured with user permissions
- Add a custom filter to a list page. This is a separate JsonFetch query. It can be an on/off filter or it can be parametrized by a user value. For example we can ask the user for a search text and search over multiple fields.
- Allow (some) users to add personal filters (including a custom fetch filter)
- Allow (some) users to define queries for exporting records.
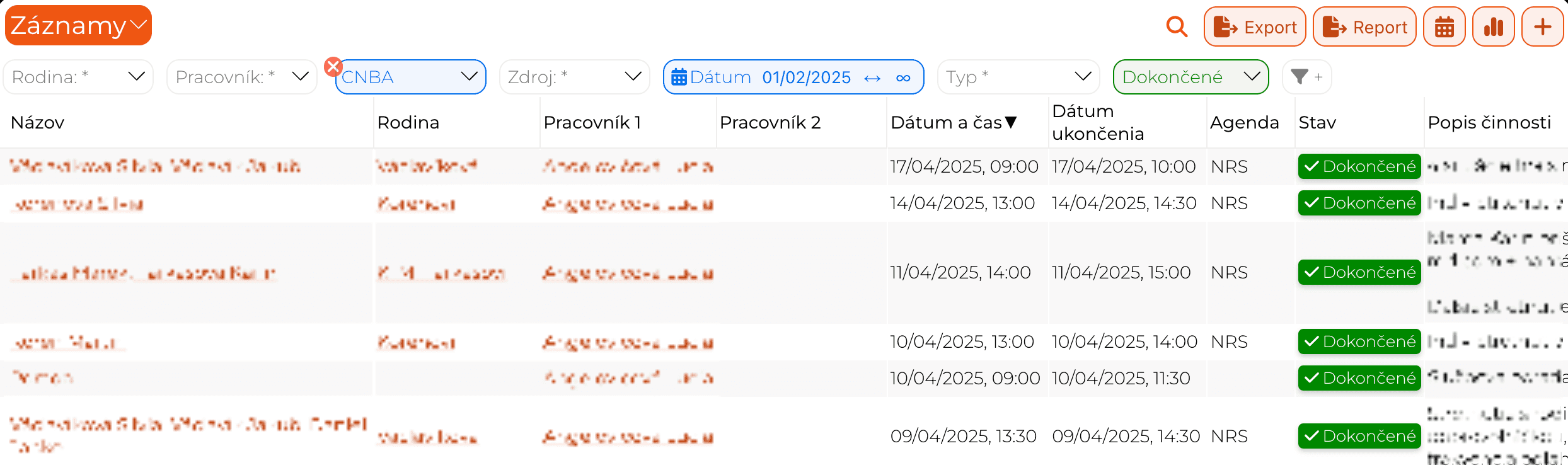
App users can
- Select between object lists.
- Sort by any column and search by name.
- Use field level filters in object lists.
- Add custom personal filters.
- Use the query builder to create exports
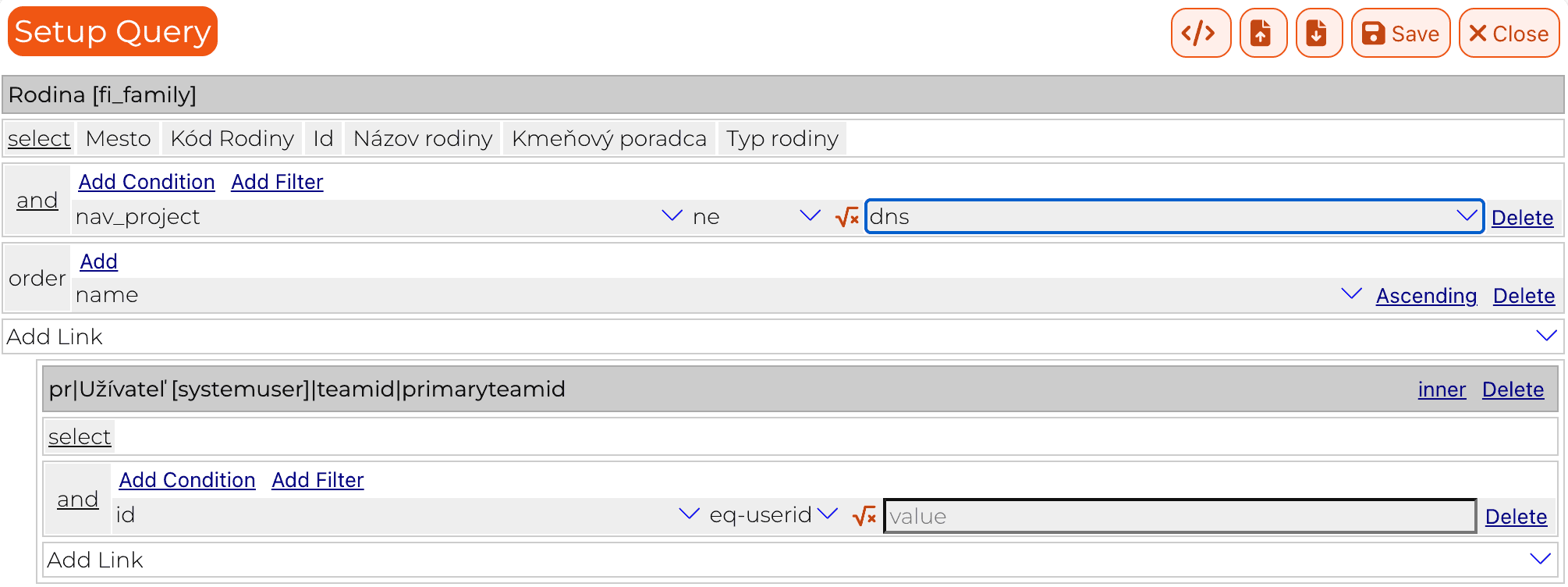
Important note here is that the object list filters are composed with the list query, and thus can only further limit the results. Furthermore, the filters or in fact JsonFetch is always constrained to the records defined by the user’s role based access rights. Or in other words, the query cannot be used to widen user access.
Wrap
Searching, filterig, slicing and dicing of data is a big part of our users work days.
We strongly believe that common tasks need to be easy and less-common possible.
Therefore our apps offer multiple query tools, that can be further customized by admins to fit your users needs.
Do you think there is a search tool missing? Or would you like to see the tools in actions?
Please get in touch.
Continue reading
Look what the bunny dragged in


One of the newer addition to Easter is for apps to hide “easter eggs”. In case you missed it, an app’s easter egg is a hidden, usually fun feature or animation accessible only with an obscure key combination.
But is not always fun and games that are…
SMS Notifications


Do you remember the time before digital calendars and reminders?
When dinosaurs roamed the world and you had to whack your dinner over the head.
Or something like that.
Interactive charts manual


A chart manual for Inuko apps.
Interactive charts are available for any list of records in the app.
That means, that any time you see a list of records in the app,
you can also have a visual chart representation of them.