Are you building a new app or service?
Are you wondering how and where to store data?
Let me tell your our experience.
The case for SQL
Relational database and the associated language SQL is by far the most common way to store and retrieve information.
Whenever you need to store data SQL is the gold standard default.
Well, unless the data is media or large documents, in which case it might be a good idea to store the metadata in the SQL daatbase and keep the visual bits in blob storage. (If you are interested here is blog post on why this is a good approach).
In this blog we will
- Which SQL database is a good fit for you
- How to deploy SQL databases and when?
- Discuss code for working with SQL in NodeJS
Top 3 reasons why you should use SQL:
- Relationship model - can be adapted cleanly to most data structures. Whether you have customers with orders, teachers with classrooms, they are relationships.
- ACID - data security in face of multiple connections and failing hardware. Data is either there or it isn’t, with clear rules what happens under what circumstances.
- Standard (ok relative), which means a massive pool of tools, solutions and experienced talent.
Yes, there are specialized databases and yes there are document storage aka nosql databases. In our opinion these are optimizations and very rarely worth the trouble. Of course, we encourage you to research available options if your data does not use relationships, or you need geographical/spacial or other specialized query operations.
Then there is the scenario where your data storage is dictated by the existing environment. Be it legacy apps you need to interface with, or the choice of the app framework. Here going with the flow has the potential of the least amount of code (and bugs). Therefore it is well worth exploring before introducing another storage system.
With all the disclaimers finished, we can now safely declare that in all other cases, which is the wast majority, when starting a new app your data storage needs are covered with SQL (and blob storage).
Choose an SQL vendor
The SQL language is largely standardized, and most vendors offer similar standard data types and features.
Full stop.
When researching which engine is the best, fastest, most efficient, you either get fanboy answers or a it depends.
Rarely you might find an expert answer: you can optimize any SQL query for any engine. There isn't one best db engine.
95% of all SQL queries will have similar performance and will be optimizable by the same tools (proper index).
The 5% might not matter in your case. Or they might be what's unique for your app.
The long (and maybe not really helpful) anwser is:
What are the most critical queries you will need? Can you express them in standard SQL, of where, join and group-by?
If you struggle to find the correct syntax, or there are no standard operators for your query, then it makes sense to look at what non-standard vendor specific SQL can do for you.
Let's look at some examples of that.
Row versionning
Why would you need that? For example when you need to keep two databases in sync. This feature allows you to initially do a full copy and then incrementally download only whatever changed.
A database engine will update the record’s row-version with the last transaction-id that modified the record.
What's great is that the transaction-id is unique and only grows.
(Records in a db are modified as part of a transaction (if you dont start a transaction explicitly it is started implicitly).
Now lets say you need to get all changed in records in a db table.
Easy SELECT * FROM products WHERE rowversion > 'min-active-row-version'
MSSQL offers a special data type called rowversion that is extremely valuable for optimistic locks and data synchronization.
There is a similar feature xmin in PostgreSQL, but the type is 32bit and thus requires maintenance to prevent overflows from causing problems.
For completeness we’ll mention that MySQL only offers a distant cousin of rowversioning - the auto updated timestamp column type. Since it only offers one second resolution, it might not catch sub-second modifications and thus is not as reliable as the versioning of MSSQL and PostgreSQL.
Collation - Text search and text order
Collation is the technical term for rules of how to compare two text strings.
Is a < b, what about a < B ? Or ä < B.
Now this might sound technical, but most users will expect sorting by name to be case insensitive and search to be case and accent insensitive. Searching for “mull” should return records with Müller.
MSSQL provides a list of collations you can choose for your db and case and accent insensitive is available. If you choose it, then
SELECT name FROM users WHERE name LIKE "mull%" will return Müller (if he is among you users;).
PostgreSQL has support for collations, but to implement the above is waaay more complicated. Take a look here.
SQLite has only binary, ascii and nocase collations out of the box. But you can build your own copy of sqlite from source code and add the ICU extension. Now the LIKE operator and order is case insensitive, but it doesn’t help with accents. For that you’ll have to modify some C code. And, sadly, the SQLite lib that is shipped with iOS (and some Android versions) comes without icu... thus if sensible user friendly sort and search is your requirement, you are going get your hands dirty.
MySQL has builtin support for collation similar to MSSQL, and even uses the case and accent insensitive one by default!
Yay.
It is also quite easy to setup a different collation on a per db, table or column level.
JSON
Ever since the Web eat the world, the dominant data exchange format became JSON, replacing the former champion XML.
Thus DB engines adapted to this brave new world and implemented many JSON-related features.
We can categorize the features into two categories.
First are the ways how the response from an SQL query can be turned into JSON.
Let's say we have a classic JS frontend, app service and SQL database.
If we can ask the SQL engine to return JSON, our app service can pipe the results to the frontend.
Without parsing, re-encoding, or otherwise packaging the data.
Less work for the app service means more performance and less expense!
Our favorite is the MSSQL implementation. By adding FOR JSON PATH to an SQL query, the results are neatly turned into an JSON array of objects.
SELECT FirstName, LastName,
Title As 'Info.Title',
MiddleName As 'Info.MiddleName'
FROM Person
FOR JSON PATH
Will return
[{
"FirstName": "Terri",
"LastName": "Duffy",
"Info": {
"Title": "Dr.",
"MiddleName": "Lee"
}
}, {
"FirstName": "Gail",
"LastName": "Erickson",
"Info": {
"Title": "Ms.",
"MiddleName": "A"
}
}]
It is possible to achieve a similar result with PostreSQL and MySQL, alhought it is much more verbose.
Here is the PostreSQL version:
SELECT json_agg("FirstName", "LastName",
json_build_object('Title', Title, "MiddleName", MiddleName) AS "Title")
FROM Person
Second are the methods in which data stored as JSON in the SQL database can be manipulated (queried, filtered, etc.) directly from SQL.
To extract a value from JSON stored in a DB table column, we can use the JSON_VALUE function. This is supported by MSSQL, MySQL and PostgreSQL, but details vary.
All db engines provide tens of features related to JSON. MySQL has 30+. It is likely you'll be able to achieve your objective with any of the engines, but you'll need to test to see which allows for the most succinct solution.
So what's the lesson here?
You need to consider your requirements and decide.
Whether features like rowversioning, collation, or json is something you care about, and what its priority is.
As you've seen, solution exists for most engines, but their complexity differs and they will tie you to your choice of database vendor.
Database vendors
- MySQL oracle - the most well know tool tied to this db is Wordpress. Since Oracle took over, there is some fragmentation. There is the fork MariaDB. This is free and opensource, but also has commercial support. Then the MySQL which has a limited free and opensource version and a more advanced commercial version.
- PostgreSQL - open source db. Odoo (formelly openerp) is a user of this db.
- Oracle Database - one of the oldest dbs. The oracle business practices are legendary, so if you haven’t heard they are easy to find on the internet.
- SQLite - open source. This db engine is designed to be embedded as a component in your app directly. This makes it unique among the lineup. The rest come as a network service (app) that multiple client apps connect to. A significant percentage of mobile apps on iOS and Android use SQLite.
- MSSQL server - Microsoft SQL Server is another engine with a long history. Stack Overflow is one of the well known brands utilizing this db engine.
If you are building a mobile app and you need local on device storage, SQLite is the only game in town.
If you are building a desktop app or a webapp (service) read on.
First some quick tips.
- If you want to go with Azure, Azure SQL is a friction less choice. MSSQL is the default choise, but MySQL and PostgreSQL are also available.
- If you wish to use open source (and or free) solution. MariaDB is recommended as being faster for read-heavy scenarios, while PostgreSQL has more advanced features. Keep in mind that MariaDB allows you to choose the “driver” and some driver are very fast but without ACID guarantees!
- If you wish to go with Amazon then RDS has both MariaDB and PostgreSQL. They also offer a database engine called Aurora which claims to be MySQL and PostgreSQL compatible.
Having evaluated the database feature set, we have to look at hosting options. Where the 1s and 0s will live.
This is where it gets tricky as the question needs to be evaluated in a larger scope. By which I mean, we need to first decide where the whole app will live and what the solution architecture will look like.
Deployment
1. Managing your own db server
The db server would be installed as a virtual machine or a container. All cloud providers support this configuration with virtually any db engine. Benefits
- Cloud provider agnostic, you can also run the same images in your local data center
- You decide all configuration parameters
- You can install additional db plugins
- Low level access to db files and partitions
Cons:
- You have to manage everything.
- You have to deploy remote logging for db and system resources.
- Backup, restore, encryption is all in your hands.
- Redundancy and failover has to be configured manually.
- Db tuning is your responsibility
2. Managed db server - SQL database as a service
Benefits
- Cloud providers provide easy to use backup, restore and security tools. With redundancy configuration and automatic failover settings.
- Azure has built in performance monitoring and performance tuning. It will continuously analyze db queries and suggest (for example) index creation.
- The db engine is kept up to date, patched and updated by cloud vendor.
- The db engine availability is also the responsibility of the cloud vendor.
Cons:
- Price: usually more expensive. If multiple database will be deployed (as is common in a saas multi-tenant apps, with a db per tenant=customer) then using a db pool will bring the cost down.
- Less flexibility: since there is no virtual machine or a db server, some parameters cannot be configured. Only the latest db engine version is available and usually plugins cannot be installed.
- Fewer choices: not all db engines are available as managed. Azure has mssql, MariaDB and PostgreSQL, Amazon RDS has Aurora, MariaDB and PostgreSQL. Google cloud - Cloud SQL offers MySQL and PostgreSQL.
Side note: AWS offers RDS custom for MSSQL and Oracle. This is hybrid solution, where you can in-fact access the db engine and the OS it is installed on, while also getting some benefits of ease-of-use and automated db provisioning, backup and restore. We consider this a solution for very specific scenarios. It might also be the most expensive solution. Please make sure you double check your requirements and this hybrid approach is truly necessary.
Google Cloud SQL mentions MSSQL. The mssql link in the docs just point to a github repo, so I let you decide whether that's good enough;)
Which deployment is for me?
If you are building a solution for a single customer, who will have one (or very few) databases, you might consider a single virtual machine with MySQL or PostgreSQL in a Docker container.
Of course it depends on your scenario. We have worked with customers with tens of users and a < 1GB database, where the app happily run on a 2GB Linux VM with NodeJS app server and PostgreSQL.
It takes only a couple of minutes and bucks to get started, look here for example digital ocean.
But, remember backup and restore along with all status and performance monitoring is on your shoulders.
If you rather not deal with keeping the db server running and patched, and worry about backup safety, consider a Managed DB Server.
For high availability and dynamic scaling, even for a single customer, a Managed DB Server might make your life easier. And cheaper, since you don't have to pay for a beefy machine, if the maximum power is needed only rarely.
For a SaaS solution with per customer database, Managed DB Server should be your default choice.
Practise time: Azure SQL with nodejs.
Prerequisites
- In your azure environment create an SQL Database pool.
- Create one or more database. We will show how to create databases from code later on.
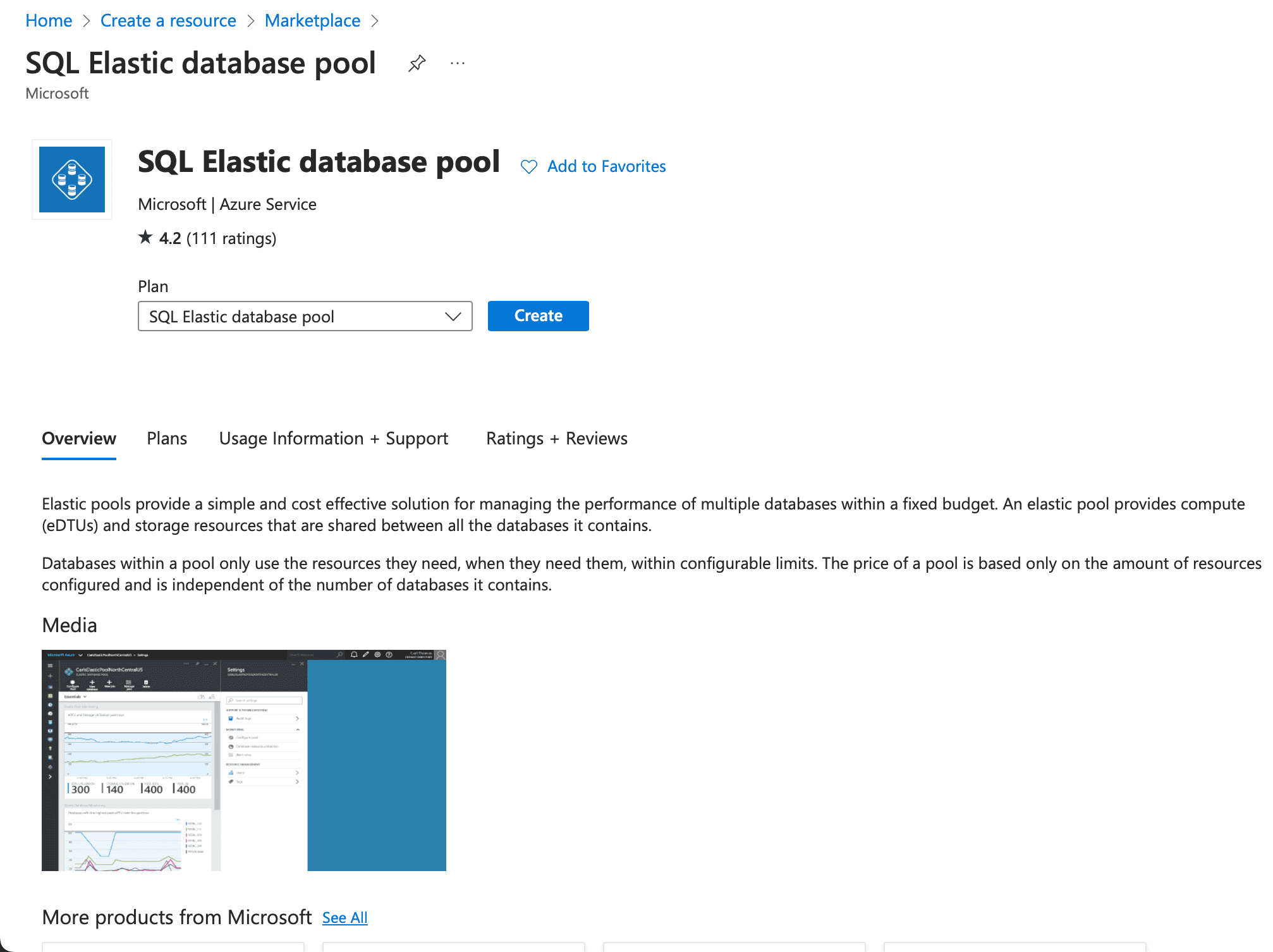
In your nodejs project
- Install the Tedious packages
npm install tedious
npm install @types/tedious --save-dev
Let’s build some helper classes
- Connection pool
- Db access class
- Db provisioning
Connection pool
Connection pool is an optimization technique that is almost always used. The idea is quite simple, instead of creating a new connection to the db engine (the db server) each time it is required, we will keep the connection around for a little while and reuse it.
The code below is used for a multitenant app service with a fixed maximum of connections per tenant and fixed time to keep an unused connection alive.
- We check if we have a connection that is not in use for the tenant. If yes we are done.
- We check if we already reached the maximum number of connections for the tenant. If not we start a new connection.
- We wait until a connetion is available.
Connections from the pool are requested with connect and must be returned to the pool with release.
You should always release the connection in a finally block.
The code below is built around the _waiters list.
Whenever a new connection comes online or a previous connection was released, we look into the waiters and give the connection to the first waiter. Look at the onConnectionReady method for details.
If a connection is not used for a configurable time, it will remove itself from the pool (to conserve server resources).
import { Connection, ConnectionConfig, ISOLATION_LEVEL, ParameterOptions, Request, TediousType, TediousTypes, TYPES } from "tedious";
// Create connection to database
const config = {
authentication: {
options: {
userName: process.env.AZURE_SQL_USER
password: process.env.AZURE_SQL_PASSWORD
},
type: "default"
},
server: process.env.AZURE_SQL_SERVER
options: {
database: process.env.AZURE_SQL_INITIAL_DB
encrypt: true
}
};
// simple logger -> replace with your favorite
const logger = (c: DatabaseConnection, msg: string) => {
console.log(c.orgName + "-" + c.connectionId + " | " + (new Date().toISOString()) + " | " + msg);
}
let connectionId = 1;
export class Database {
_waiters: {
caller: string,
orgName: string,
res: (db: DatabaseConnection) => void,
rej: (x: any) => void,
timeout: NodeJS.Timeout,
traceStart: [number, number]
} [] = [];
public async connect(orgName: string, caller: string, retry: number = 0): Promise<DatabaseConnection> {
const c = this._connections.find(x => !x.inUse && x.orgName === orgName);
if (c) {
logger(c, "SQL Reused:\t" + caller);
c.inUse = true;
return c;
}
let perOrgCount = 0;
for (const x of this._connections) {
if (x.orgName === orgName)
perOrgCount++;
}
if (perOrgCount < 4) {
const onConnectionReady = (db: DatabaseConnection) => {
for (let i = 0; i < this._waiters.length; i++) {
const waiter = this._waiters[i];
if (waiter.orgName === db.orgName) {
this._waiters.splice(i, 1);
clearTimeout(waiter.timeout);
logger(db, "SQL Connect: " + duration.toFixed(0) + "ms\t" + waiter.caller);
db.inUse = true;
waiter.res(db);
return;
}
}
// connected but nobody needs us:( This can easily happen if the waiter who started this connection
logger(db, "SQL Connection not needed");
}
const myId = connectionId++;
const cfg = JSON.parse(JSON.stringify(config));
if (orgName === "master")
cfg.options.requestTimeout = 1000000;
cfg.options.database = orgName;
const newCon = new Connection(cfg);
const db = new DatabaseConnection(newCon, orgName, myId, onConnectionReady);
this._connections.push(db);
// ASYNC! the connection might get established, but the waiter was meanwhile served
// on a different connection that was returned to the pool earlier.
newCon.on("connect", err => {
if (err) {
dropConnection("Cannot connected:", err);
} else {
// mark db as not inUse. It is created with the flag set, to prevent somebody from using it while connecting
db.inUse = false; //
onConnectionReady(db);
}
});
const dropConnection = (msg: string, err?: any) => {
const idx = this._connections.findIndex(x => x._connection === newCon);
if (idx >= 0) {
logger(db, "SQL Connection dropped from pool on " + msg);
this._connections.splice(idx, 1);
} else {
logger(db, "SQL Connection not in pool!");
}
};
newCon.on("end", () => dropConnection("end"));
newCon.on("error", err => {
logger(db, "SQL Connection Error:" + err);
})
newCon.connect();
// yes, we continue below.
}
const z = new Promise<DatabaseConnection>((res, rej) => {
const timeout = setTimeout(() => {
let index = this._waiters.findIndex(x => x.timeout === timeout);
this._waiters.splice(index, 1);
rej(new Error("Error: connection timeout"))
}, 15000); // wait 15 seconds for a connection
this._waiters.push({ orgName, res, rej, timeout, traceStart: process.hrtime(), caller: caller });
});
return z;
}
private _connections: DatabaseConnection[] = [];
}
export class DatabaseConnection {
constructor(connection: Connection, orgName: string, id: number, onConnectionReady: (db: DatabaseConnection) => void) {
this._connection = connection;
this.inUse = true;
this.orgName = orgName;
this.connectionId = id;
this._onConnectionReady = onConnectionReady;
}
private _onConnectionReady: (db: DatabaseConnection) => void;
public _connection: Connection;
public connectionId: number;
public inUse: boolean;
public orgName: string;
public release() {
this.inUse = false;
this.scheduleTimeout();
this._onConnectionReady(this);
}
private scheduleTimeout() {
if (this._timeout)
clearTimeout(this._timeout);
this._timeout = setTimeout(() => {
if (this.inUse) {
// in use, wait for release.
//this.scheduleTimeout();
} else {
this.inUse = true; // do not let anyone use this connection while closing.
console.log("Connection open for 10 seconds, closing.");
this._connection.close();
}
}, 10000);
}
private _timeout: any;
// more code in the next section.
}
Database access
The code below provides an interface for simplifying SQL access and forcing the use of SQL parameters to prevent SQL injection bugs.
SQL INSERT, UPDATE and DELETE statements are built as parametrized queries.
No need to remember the SQL syntax and you will only have a single place where the parameters are prepared.
export class DatabaseConnection {
// more code in the previous section.
public async traceSqlQuery(start: [number, number], sql: string, parameters?: SqlParam[]): Promise<void> {
const end = process.hrtime(start);
const duration = (end[0] * 1000) + (end[1] / 1000000);
// put your logging here...
// if (duration > 1000) {
// ....
//}
}
public async executeQuery(sql: string, parseJson: boolean = true, parameters?: SqlParam[]): Promise<any> {
const p = new Promise((res, rej) => {
let jsonText = "";
const traceStart = process.hrtime();
const request = new Request(
sql, //`SELECT * from TEST FOR JSON PATH`,
(err, rowCount) => {
this.traceSqlQuery(traceStart, sql, parameters);
if (err) {
rej(new Error(err.message));
} else {
if (parseJson) {
const json = jsonText ? JSON.parse(jsonText) : [];
res(json);
}
else {
res(jsonText);
}
}
}
);
if (parameters) {
this.addRequestParameters(request, parameters);
}
request.on("row", columns => {
if (!columns || columns.length < 1) {
//res({});
} else {
jsonText += columns[0].value;
}
});
this._connection.execSql(request);
});
return p;
}
private addRequestParameters(request: Request, parameters: SqlParam[]) {
const numericOptions: ParameterOptions = { scale: 10, precision: 23 };
for (let i = 0; i < parameters.length; i++) {
const type = parameters[i].type;
const options = type === TYPES.Decimal ? numericOptions : undefined;
request.addParameter("P" + i, type, parameters[i].value, options);
}
}
public async beginTransaction(): Promise<void> {
const p = new Promise<void>((res, rej) => {
this._connection.beginTransaction((err) => {
if (err)
rej(err);
else
res();
});
});
return p;
}
public async finishTransaction(rollback: boolean = false): Promise<void> {
const pr = new Promise<void>((res, rej) => {
if (rollback) {
this._connection.rollbackTransaction(err => {
if (err)
rej(err);
else
res();
});
}
else {
this._connection.commitTransaction(err => {
if (err)
rej(err);
else
res();
});
}
});
return pr;
}
public async executeNonQuery(sql: string, values: SqlParam[]) {
const p = new Promise<number>((res, rej) => {
const traceStart = process.hrtime();
const req = new Request(sql, (err, count, rows) => {
this.traceSqlQuery(traceStart, sql, values);
if (err)
rej(err);
else
res(count);
});
this.addRequestParameters(req, values);
req.on("row", columns => {
if (!columns || columns.length < 1) {
//res({});
} else {
//jsonText += columns[0].value;
console.log(columns[0].value);
}
});
this._connection.execSql(req);
});
return p;
}
public async insertRow(tableName: string, values: SqlParam[]) {
const sql = "INSERT INTO " + tableName + " ( " +
values.map((v) => v.name).join(",") + " ) VALUES (" +
values.map((v, i) => "@P" + i).join(",") + ")";
return this.executeNonQuery(sql, values);
}
public async updateRowWithId(tableName: string, id: SqlParam[], values: SqlParam[]) {
const sql = "UPDATE " + tableName + " SET " + values.map((v, i) => v.name + "=@P" + i).join(", ");
return this.executeNonQueryWhere(sql, id, values);
}
public async deleteRowWithId(tableName: string, id: SqlParam[]) {
const sql = "DELETE FROM " + tableName;
return this.executeNonQueryWhere(sql, id, []);
}
private async executeNonQueryWhere(sql: string, conds: SqlParam[], values: SqlParam[]) {
values = values.slice() || [];
if (conds && conds.length > 0) {
sql += " WHERE ";
for (let i = 0; i < conds.length; i++){
if (i > 0)
sql += " AND "
const id = conds[i];
sql += id.name + "=@P" + values.length;
values.push(id);
}
}
return this.executeNonQuery(sql, values);
}
}
Usage
Now that we have a connection pool and a query interface, let's look at how to use them.
The sample below retrieves a user by email from a tenant's (orgName) database.
It will also quickly check whether the user has not been disabled.
Note the FOR JSON PATH which instructs the MSSQL engine to return records as JSON.
// Declare once!
const dbMgr = new Database();
const getUser = async (orgName: string, email: string): Promise<IDbUser| undefined> => {
let db;
try {
db = await dbMgr.connect(orgName, "getUser");
let ok = false;
const o = await db.executeQuery('SELECT * FROM systemuser WHERE emailaddress=@P0 FOR JSON PATH', true,
[{ name: "P0", type: TYPES.NVarChar, value: email }]) as IDbUser[]
if (o && o.length > 0) {
if (o[0].status === "inactive")
throw Error("Profile disabled");
return { ...o[0], orgName: orgName };
}
return undefined;
}
finally {
db?.release();
}
}
const disableUser = async (orgName: string, email: string): Promise<void> => {
let db;
try {
db = await dbMgr.connect(orgName, "disableUser");
// Version 1: fetch id and update
const users = await db.executeQuery('SELECT id FROM systemuser WHERE emailaddress=@P0 FOR JSON PATH', true,
[{ name: "P0", type: TYPES.NVarChar, value: email }]) as {id:string}[];
if (users && users[0]) {
await db.updateRowWithId("systemuser", [{ name: "id", type: TYPES.UniqueIdentifier, value: users[0].id }], [
{ name: "status", type: TYPES.NVarChar, value: "inactive" }
// add modifiedon or other values...
]);
} else {
throw Error("User not found: " + email);
}
return;
// Version 2: user email as id.
const rowsAffected = await db.updateRowWithId("systemuser", [{ name: "emailaddress", type: TYPES.NVarChar, value: email }], [
{ name: "status", type: TYPES.NVarChar, value: "inactive" }
]);
if( rowsAffected === 0) {
throw Error("User not found: " + email);
}
}
finally {
db?.release();
}
}
Create a new Database
The code below will create a new database in the Azure SQL pool.
This will take a while... 1-2 minutes.
While you can create an empty database, it is much easier to create a basic skeleton db and use the AS COPY OF syntax.
That's what we will be using below.
interface IDatabaseCreateRequest {
organization: string;
username: string;
email: string;
password: string;
}
const DatabaseCreateRequests: IDatabaseCreateRequest[] = []; // Trial orgs to be created
let CreateRequestRunning: boolean = false;
const checkOrgState = async (db: DatabaseConnection, org: string) => {
const rec = await db.executeQuery("SELECT * FROM sys.databases WHERE name=@P0 FOR JSON PATH", true,
[{ name: "P0", type: TYPES.NVarChar, value: org }]);
if (rec && rec.length > 0) {
if (rec[0].state === 0) // state will be 2 while deployment is in progress...
return 0;
console.log("DBSTATE:" + rec[0].state);
return 1;
}
return undefined;
}
const createDatabaseThread = async () => {
const trial = DatabaseCreateRequests[0];
if (!trial) {
CreateRequestRunning = false;
return;
}
let db;
try {
db = await dbMgr.connect("master", "createOrgThread");
await db.executeNonQuery(`CREATE DATABASE ` + trial.organization + ` AS COPY OF demo`, []);
let s: number|undefined = 1;
for (let i = 0; i < 1000; i++) {
s = await checkOrgState(db, trial.organization);
if (s === 0)
break;
await sleep(1000);
}
if (s === 0) {
// Insert user as admin -> provide your code here.
insertUserAsAdmin(db, trial.username, trial.password, trial.email);
sendWelcomeEmail(trial.email, trial.organization);
} else {
// sendError... unable to create db...
}
}
catch (ex) {
console.log(ex);
}
finally {
db?.release();
}
DatabaseCreateRequests.shift();
if (DatabaseCreateRequests.length > 0) {
setTimeout(createDatabaseThread, 1);
} else {
CreateRequestRunning = false;
}
}
const createDatabaseForOrganization = async (reqBody: any): Promise<number> => {
const organization = sanitizeOrgName(reqBody["organization"]);
if (DatabaseCreateRequests.find(x => x.organization === organization)) {
return 1; // in progress
}
let db;
let dbState: number|undefined = undefined;
try {
db = await dbMgr.connect("master", "createTrialOrg");
dbState = await checkOrgState(db, organization);
}
finally{
db?.release();
}
if (dbState === undefined) {
DatabaseCreateRequests.push({
organization: organization,
username: sanitizeName(reqBody["person"]),
email: sanitizeEmail(reqBody["username"]),
password: sanitizePassword(reqBody["password"])
});
if (!CreateRequestRunning) {
CreateRequestRunning = true;
setTimeout(createDatabaseThread, 1);
}
dbState = 1;
}
return dbState;
}
app.post("/api/trial", noAuth, async (req, res, done) => {
try {
// The javascript client side code will call this in a loop while 201 status is returned.
const dbState = await createDatabaseForOrganization(req.body);
if (dbState === 0) {
passport.authenticate("local")(req, res, (err: any) => {
if (err) {
res.redirect("/login");
}
else {
res.status(200).send("OK");
}
});
return;
}
res.status(201).send("WAIT");
}
catch (err) {
res.status(500).send("Trial Error: " + (err as Error).message);
}
});
Case closed?
SQL should be your default choice of data storage, but as we've seen above it is not quite that simple.
We explored the practicalities of choosing and deploying a SQL database.
And we looked at some common code, useful when working with an SQL database.
Let us know, if you found the content/code useful, or if there is a topic you would like to know more about.
Happy hacking!
Continue reading
Sepa mass payment ISO20022


QR codes are a great way to quickly create a single bank payment. But what if you need to create multiple payments and regularly? There is a file format standard for that! Let’s look at how to build Sepa mass payment.
Making Addresses Work


There are many reasons to visit a client. Whether it is for therapy, for sales or for delivery, the journey cannot start without an address.
SQL OR condition on joins


Queries with OR conditions are notorious for being hard to make fast.
Avoid them if you can, read on if you cannot.